
What started in 1989 as an e-mail list for a few dozen string theorists has now grown to a collection of more than two million papers—and the central hub for physicists, astronomers, computer scientists, mathematicians and other researchers. On January 3 the preprint server arXiv.org crossed the milestone with a numerical analysis paper entitled “Affine Iterations and Wrapping Effect: Various Approaches.” The Library of Alexandria, for comparison, is believed to have contained no more than hundreds of thousands of manuscripts.)
“We’re a way for authors to communicate their research results quickly and freely,” says Steinn Sigurdsson, a professor of astrophysics at Pennsylvania State University and arXiv’s scientific director. Unlike traditional scientific journals, arXiv (pronounced “archive” because the “X” represents the Greek letter chi) allows scientists to share research before it has been peer-reviewed.
When submitting to traditional journals, authors frequently wait half a year or more to publish; papers typically appear on arXiv within a day. Authors often submit manuscripts to arXiv and then subsequently publish them in a peer-reviewed journal, but increasingly, papers are released on arXiv alone. Beyond traditional manuscripts, arXiv also contains white papers, historical overviews and even cheeky April Fools’ Day papers.
“It’s like the backbone for our field,” says Alex Kohls, head of the Scientific Information Service at CERN, the world’s premier organization for particle physics research, located near Geneva. “It’s not only a tool for physicists and computer scientists—it has had an impact on the overall scholarly communication process.” For instance, arXiv-inspired preprint servers in the life sciences, such as bioRxiv and medRxiv, have proved invaluable for speeding up biomedical research during the coronavirus pandemic.
Growth has been explosive. In 2008, 17 years after it went online, arXiv hit 500,000 papers. By late 2014 that total had doubled to one million. Seven years later arXiv has doubled its library again but continues to grapple with its role: Is it closer to a selective academic journal or more like an online warehouse that indiscriminately collects papers?
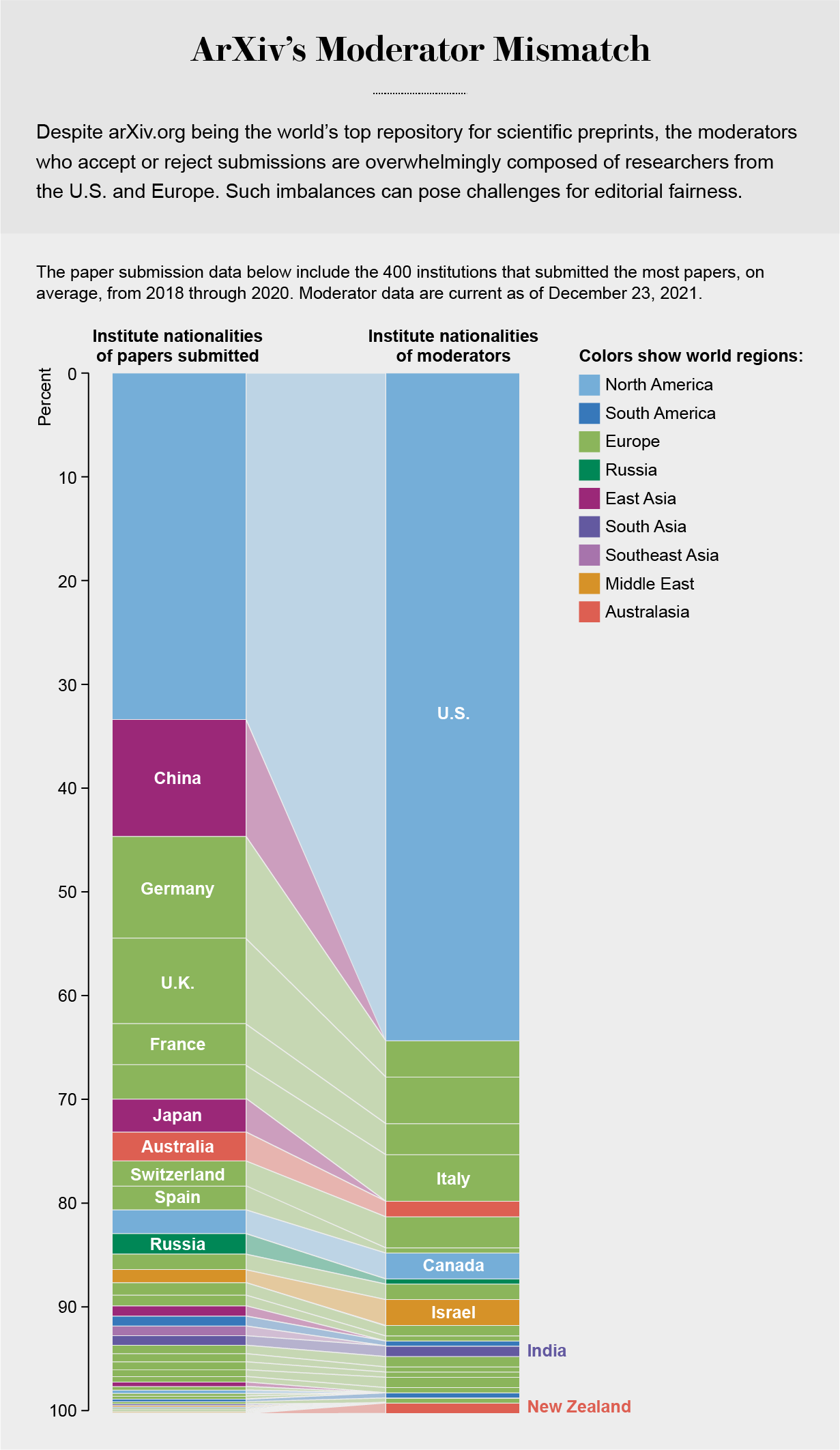
Amid this confusion, some researchers are concerned about arXiv’s moderation policies, which they say lack transparency and have led to papers being unfairly rejected or misclassified. At the same time, arXiv is struggling to improve the diversity of its moderators, who are predominantly men based at U.S. institutions.
Among physicists, there is a common refrain: “If it’s not on arXiv, it doesn’t exist.” In other words, for a wide swath of research disciplines, arXiv has become indispensable, part of the scientific process itself. For the researchers that use it, arXiv is part of their everyday workflow: they may browse new releases with their morning coffee, submit a paper by noon and download reading material in the evening. This outsize role testifies to arXiv’s success but also shows how the repository’s problems are not just its own—they are science’s, too.
Catastrophic Success
Before arXiv existed, physicists had a tradition of mailing preprints. Paper copies of manuscripts that had yet to clear peer review were sent around the globe to libraries at laboratories and universities to be perused by readers eager for the freshest scientific news. Over time, the volume of preprints became immense, and mail became e-mail. Then, in 1991, Paul Ginsparg, now at Cornell University, took his fellow physicist Joanne Cohn’s e-mail list and automated it into a repository anyone could submit to and access. The effect was immediate.
“Within a couple of years, more or less every article in particle physics was first submitted to arXiv,” Kohls says. Thanks to its impressively speedy posting times and subsequent widespread adoption across other fields of physics, math and computer science, arXiv rapidly became the primary place to check for new results instead of traditional journals or conferences.
“A telescope saw something on Friday. By Monday there are papers on it. By Tuesday there are papers rebutting the papers that came out on Monday,” Sigurdsson says. “It’s fun. It’s exciting.”
Lanu Kim, a researcher now at the Korea Advanced Institute of Science and Technology, led a study that found authors of highly-cited arXiv papers are increasingly likely not to bother publishing in a traditional journal at all. “If they have gained enough interest from arXiv, they may choose not to go through these hassles in the journal publication process,” Kim says. Her work found traditional journals still had an important impact on citations, but they acted more as a curator than a distributor of research.
In spite of its success, arXiv has continuously struggled with stability and resources. The server has undergone upheaval, moving its location within Cornell. Currently, there is funding for only a handful of staff to help volunteer moderators handle up to 1,200 daily submissions. “We’re an old classic car, and the rust has finally come through, and the pistons are wearing out,” Sigurdsson says. “We are understaffed and underfunded—and have been for years.”
Similarly, arXiv’s growth as an institution has not kept pace with the growth of the scientific communities that rely on it. “It was, for a very long time, basically run with a few people,” Kohls says. Even today there are just about 200 volunteer moderators for roughly 150 categories, and they each may deal with up to 30 papers a day—a factor that has led to delays and other issues.
Everything in Moderation
When an author submits a paper, it enters a queue for routine evaluation by a moderator. If the moderator does not flag the paper as somehow problematic, it is usually posted the next day. But moderators frequently intervene, delaying posting by days or weeks, reclassifying papers or even outright rejecting submissions.
“They are taking actions which seem to go against what the role of a preprint server should be,” says Deepak Vaid, a physicist at the National Institute of Technology Karnataka, Surathkal, in India. Vaid points to what he says is inconsistent moderation and a lack of transparency.
Delays may seem minor, but to scientists racing to be first to announce some discovery or bold new hypothesis, even a few days can be critical. By reclassifying papers to arXiv’s “general” categories—a catch-all grouping often filled with research of dubious quality—moderators can effectively silo submissions they feel do not meet a more refined category’s standards. Finally, moderators can simply reject papers.
“We have to draw lines,” Sigurdsson says, pointing to the fact that arXiv sometimes receives submissions that are likely pseudoscientific, such as ones in which an author claims to have “proved Einstein wrong” or to have constructed a “theory of everything.” To prevent an influx of crackpottery, arXiv mandates that submitting authors must be “verified.” Originally, verification was based on academic affiliation, but today it can alternatively rely on an “endorsement” system: anyone can submit so long as a verified user who has authored a certain number of papers within the same “subject domain” vouches for them. “We’re sort of limping along with it because it’s better than nothing,” Sigurdsson says.
Vaid agrees that endorsements or other verification systems are necessary to weed out pseudoscience. But he says that because preprint servers are not journals, arXiv and its moderators should simply relax their standards and be less heavy-handed with rejections.
Sigurdsson raises a counterargument. “If the signal-to-noise ratio becomes too bad, then it becomes useless. Then you might as well be reading YouTube comments,” he says. At arXiv, roughly 6 percent of submissions receive a hold, and about 2 percent are rejected. Top journals, such as Nature and Science, accept fewer than 10 percent of papers. (ArXiv’s efforts at quality control have also sparked the creation of competing preprint servers, such as viXra.org, that welcome submissions with minimal oversight. Unsurprisingly, mainstream academics consider such repositories to be of minimal utility.)
Although moderation is not peer review, arXiv’s moderators have the same power as editors to reject papers. “They perform what I’ve called ‘the one-look approximation to peer review’—no pretense of being comprehensive on rapid turnaround and applying a much lower bar,” Ginsparg says. “Their bias is always in the ‘accept’ direction, since we expect science to be self-correcting.”
For some hopeful authors, arXiv’s purportedly low bar for acceptance makes any rejection all the harder to swallow. In 2017 one of Vaid’s articles was rejected on the basis that its introduction “uses highly dramatic and misrepresentative tone.” When he asked for clarification to help rewrite the introduction, an arXiv representative responded that “moderators are not referees and do not provide details with their decisions.”
Because moderators do not have time to perform comprehensive peer review for each submission, arXiv’s policy is not to elaborate upon its rejections. “We don’t want to get into an argument,” Sigurdsson says. It is possible to appeal a rejection or misclassification, but the process is tedious—essentially replicating the hassle of peer review just to get posted on a preprint server.
In August 2021 arXiv moderators rejected a paper by highly regarded Chinese scientists Chao-Yang Lu and Jian-Wei Pan, each of whom has contributed many “firsts” in quantum research. Rather than appeal, Lu and Pan pointedly chose to release the preprint on viXra and other servers—although not before Lu publicly expressed befuddlement and frustration at arXiv’s rejection. Roberto Casadio, a theoretical physicist at the University of Bologna in Italy who independently examined the paper, could not understand why it was rejected. “It investigates a topic well within the scope of” arXiv’s category for general relativity and quantum cosmology, Casadio says. “Whether the results are correct or wrong is something that the community of arXiv readers can—and should—have the opportunity to assess independently.”
Seeking Representation
One source for some of arXiv’s woes may be its imbalanced roster of moderators. Of the repository’s approximately 200 moderators, only 13 percent are women, and as noted earlier, the majority of moderators are men based at institutions in the U.S. Many moderators have been working in their fields for decades, starting from a time when mathematics, physics and other physical sciences were even less diverse than they are now.
“It would be good if [arXiv’s moderators] reflected the demographics of essentially the equivalent of tenured research groups,” Sigurdsson admits. But recruiting new team members is hard because moderating is a largely thankless task with little to no professional rewards and plenty of downsides. Female moderators, in particular, are regular targets of abusive e-mails.
Beyond obvious imbalances in gender and nationality, Vaid points to the more insidious matter of ideological representation. When it comes to unifying quantum field theory and gravity, string theory remains far more popular than competing approaches, such as loop quantum gravity. Moderators, like journal editors, have some power to decide the kinds of theories that get published. While no solid data have been collated to confirm such suspicions, Vaid argues loop quantum gravity proponents are turned away more often than string theorists.
Whether or not diversifying moderators along all these lines would address critics’ complaints is unclear. There is, after all, no “Chinese physics” or “American math,” and members of the international scientific community have much in common. But problems with moderator diversity and issues with overzealous or inappropriate rejections may be related.
Six years ago Nicolas Gisin, a quantum physicist at the University of Geneva, claimed his students had been censored by arXiv after their paper was rejected in 2014. (A modified version of the paper subsequently passed peer review and was published in Physics Letters A in 2015.) For Gisin, the incident raised a question: To whom does arXiv belong—the staff and volunteers who run the site or the global community of scientists who supply it with research?
Ginsparg says that the original intent for arXiv was to “belong” to the larger physics community, but he points out that although the server was originally for physicists, today computer science papers constitute the plurality of submissions.
Despite arXiv being legally centered at Cornell and financially supported by the U.S.-based Simons Foundation and an international consortium of academic institutions, Kohls says, “our researchers feel like arXiv belongs to the scientific community.”
If it truly belongs to the broader scientific communities who depend on it and have filled it with two million papers, what does that imply for arXiv’s future?
For Vaid, the answer is clear: any “business as usual” approach is doomed to failure. “There is no accountability—zero, none,” he says. He believes arXiv needs to be more transparent about its criteria and to explain rejections. Sigurdsson suggests that proposals to enact more comprehensive peer review at arXiv are highly unlikely to succeed. But he says he plans to increase the number of moderators in the coming years to at least 300 so that every category has a minimum of two.
Ginsparg also acknowledges that arXiv’s unique position confers a responsibility to the community. “There is nonetheless a question of principle in having the world’s research output in many fields passing through a single portal” he says. “[ArXiv’s] actions and any unintentional biases should be continuously subject to scrutiny.”
If the current pace holds, arXiv will double its library again before the decade is out. What discoveries the next two million papers will contain are impossible to know, but it seems unlikely arXiv’s starring role in science will fade.
During recent library renovations, a survey quizzed CERN staff about what they wanted: New furniture? Better coffee? “What they said is ‘Put a big screen in there and write a script that automatically displays the new daily submissions to arXiv,’” Kohls says. “It will probably be the center of the CERN Library.”